在PostgreSQL中使用窗口函数解决取分组后前n条数据的问题
2023-02-23
先描述一个业务场景:
-
现有一张数据表,结构如下:
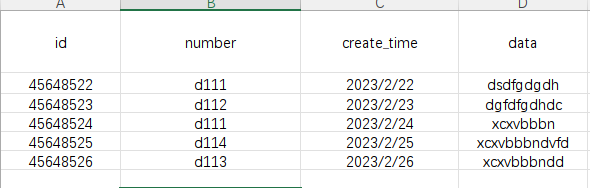
-
现在要查询每个不同
number的最后一条(create_time)的完整记录 -
保证查询结果中的
number不重复
直观的解决办法是:
- 对
number字段分组 - 对
create_time进行desc排序
如:
select *
from (select *
from table_name
where create_time > '2022-12-01'
and create_time < '2023-12-12'
ORDER BY create_time desc) a
GROUP BY number;
这条sql放在MySQL中或许可以执行成功,但在PostgreSQL中是无法执行的,因为pgsql的group by是严格的,group by后无法再select * (本文忽略select * 的性能问题,与主题无关)
在pgSQL中,有一种可行的写法:
select *, pcd.number
from table_name pcd
right join (select number, max(create_time) latest_create_time
from table_name
where create_time > '2023-02-21'
and create_time < '2023-02-22'
group by number) d
on d.number = pcd.number and pcd.create_time = d.latest_create_time
但这种写法存在一个致命的问题:
如果数据表存在有这么两条或多条记录,它们的number和create_time的值同时相等,那么:
使用上述连接查询的结果将不会将这些重复记录筛选出去,也就是说查询结果中依然有存在相同number的可能性
这显然与基本需求不符
使用窗口函数
- 窗口函数是什么:
窗口函数,也称作
OLAP函数(On-Line Analytical Processing),可以对数据库数据进行实时分析处理
- 基本语法:
-- <窗口函数> over (partition by <要分组的列名> order by <要排序的列名>)
- 有什么窗口函数:
- 专用窗口函数:
rank(),dense_rank(),row_number()等 - 普通聚合函数:
sum(),avg(),count()等
- 使用:
我们使用row_number()解决上述所有问题:
select *
from (SELECT *,
row_number() OVER (PARTITION BY number order by create_time desc ) as row_number
FROM table_name
order by number) d
where d.row_number = 1
order by create_time desc;